Storing data involves many facets that need to be considered, ranging from cost, performance, and accessibility to the specific requirements of the applications that interact with the data.
Object Storage
Object Storage is one of the three most widely used cloud storage architectures. Objects consist of the data itself, a variable number of metadata attributes, and a globally unique identifier (GUID). Object storage is primarily used for unstructured data, such as Spotify songs or images on Facebook. Services like Amazon S3, Microsoft Azure Blob Storage, OpenStack Swift, and Google Cloud Storage utilize this architecture. Data is accessed via APIs over a network.
Use Cases
- Storing unstructured data such as music, videos, or photos.
- Backup files, logs, etc.
- Data archiving.
Block Storage
Block Storage provides a fixed-size storage volume to an instance (e.g., a virtual machine). The storage typically uses standard file systems such as NTFS, FAT32, or EXT4. Examples of block storage services include AWS EBS, Rackspace Block Storage, and Azure Disk Storage. Access to block storage is only possible when it is attached to a VM and its operating system.
Use Cases
Block storage is used for databases requiring consistent I/O and low-latency connections. It can also be employed for RAID systems, linking multiple block storage devices together to perform operations like striping and mirroring. Additionally, block storage is well-suited for server-side data processing.
Distributed File Systems
Distributed file systems conceptually differ significantly from block and object storage. They need to provide functionality similar to local file systems but operate across multiple systems.
Example: BeeGFS
BeeGFS is a distributed file system developed by a Fraunhofer Institute. It offers a POSIX-like interface, allowing applications to interact with it similarly to local file systems. This enables applications running on physically separate machines to share the same file system. Unlike local file systems, distributed file systems must address challenges such as file synchronization and path resolution.
BeeGFS consists of four components:
- Management Server: Acts as a meeting point for all participating components, maintaining a list of BeeGFS services and their statuses. It is lightweight and can run on the same server as other BeeGFS components.
- Metadata Server: Stores information about files, such as ownership, access rights, and file location. File locations are managed using a stripe pattern, which distributes file chunks across participating storage nodes. While striping can enhance performance, it also introduces risks such as data loss if storage nodes fail.
- Storage Server: Stores the actual file data, known as data chunk files, using standard POSIX file systems. Unused RAM is utilized for caching.
- Client: Registers with the Linux Virtual File System interface. BeeGFS clients require a custom Linux kernel, which is automatically installed and configured.
The metadata and storage architecture follow a scale-out design, ensuring that adding more instances increases performance.
BeeGFS Architecture
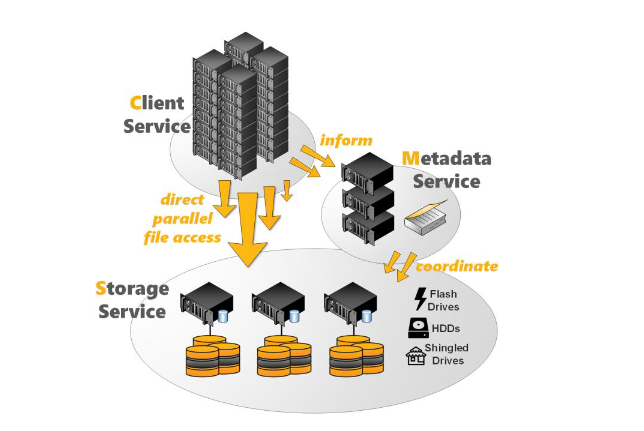
Image Source: An Introduction to BeeGFS by Frank Herold, Sven Breuner, June 2018
Other Distributed File Systems
Hadoop Distributed File System (HDFS)
HDFS is optimized for large files with a "write-once, read-many" access pattern. It uses extremely large block sizes (128 MB compared to 4 KB in local file systems). HDFS is not designed for POSIX compatibility, which limits features like modifying existing files.
Ceph FS
Ceph FS is versatile and supports three interfaces:
- Ceph Object Gateway
- Ceph Block Device
- Ceph File System
Data is stored collectively in the Ceph Storage Cluster. Ceph FS is a general-purpose distributed file system that can handle a variety of applications deployed on a virtualized cluster. It is layered on top of a distributed object store.